
Let’s face it — managing backups for an Elasticsearch cluster often feels like a chore nobody wants to deal with. But what if it didn’t have to be that way?
Imagine setting up a system where your data quietly backs itself up to secure object storage, without you lifting a finger after the initial setup. No complex tools, no expensive services — just Python, Elasticsearch, and any S3-compatible storage like MinIO.
In this guide, we’ll show you how to turn that idea into reality. You’ll learn how to automate Elasticsearch snapshots directly to S3 storage using simple Python scripts — making your backup process fast, reliable, and stress-free. Whether you’re a DevOps engineer, developer, or system admin, this approach will save you time and give you peace of mind knowing your data is always safe.

I/ Step 1: Prepare Your config.ini and Download the Automation Tools
Every great automation starts with a solid foundation. In this case, before we let Python handle the heavy lifting, we need two things:
- A simple configuration file to tell our scripts where to connect and how to behave.
- The right tools to automate both the creation of your S3 repository and the daily snapshot process.
🔹 The Power of config.ini:
Rather than hardcoding connection details into your scripts (a recipe for headaches later), we’ll centralize everything in a neat little file called config.ini. This file will store:
- Your Elasticsearch connection settings.
- And your MinIO S3 storage details, where Elasticsearch will send its snapshots directly.
Here’s what your config.ini should look like:
[elasticsearch]
es_host = https://localhost:9200
username = elastic
password = your_password
verify_ssl = False
[s3_settings]
bucket = elasticsearch-backups
endpoint = https://minio.yourdomain.com
region = us-east-1
[snapshot]
repo_name = minio_backup_repo🔸 A Quick Look at the Parameters:
[elasticsearch] Section
- es_host
The address of your Elasticsearch cluster. This could be localhost for local setups or a server IP/domain in production environments. - username & password
These are the credentials your script will use to authenticate with Elasticsearch’s API. It’s best to use a user account with permissions specifically for managing snapshots. - verify_ssl
If you’re using self-signed certificates (common in local or test environments), set this to False to bypass SSL verification. For production with properly signed certificates, always set this to True for security.
[s3_settings] Section
- bucket
The name of the MinIO bucket where your Elasticsearch snapshots will be stored. Make sure this bucket exists before running your backup scripts. - endpoint
This is the URL where your MinIO S3 service is accessible. Whether it’s hosted on-premises, in the cloud, or on a VM, this tells Elasticsearch where to send the snapshot data. - region
While MinIO doesn’t require a region, Elasticsearch expects this field when connecting to any S3-compatible storage. You can safely use us-east-1 or any placeholder value here.
[snapshot]
- repo_name
The name of the Elasticsearch repo which stores all snapshots.
With this file in place, switching environments or updating credentials becomes effortless—just edit config.ini without touching a single line of code.
🔹 Download the Python Tools:
To streamline your Elasticsearch snapshot workflow, we’ve created two lightweight Python scripts:
- create_s3_repo.py
This script helps you quickly set up an S3 repository in Elasticsearch. Just run it, enter your desired repo name, and you’re done. - daily_snapshot.py
Automates your daily index backups by triggering snapshots into your S3 repository—no more manual API calls or forgotten backups.
You can download both scripts from our GitHub repository
git clone https://github.com/vominhtri1991/elasticsearch-backup-tools.gitMake sure your config.ini sits in the same directory as these scripts.
II/ Step 2: Install MinIO, Create Your S3 Bucket, and Prepare Credentials for Elasticsearch
With our configuration file ready, it’s time to set up the storage where Elasticsearch will send its snapshots. Instead of relying on external cloud providers or complex services, we’re going to take full control by deploying MinIO — a lightweight, high-performance, S3-compatible object storage.
MinIO is perfect for this job. It’s simple to deploy, works seamlessly with Elasticsearch’s built-in S3 support, and gives you complete ownership of your backup storage, whether you’re running on a local server, VM, or in the cloud. Let’s walk through setting it up.
🌟Install MinIO as a Service:
For most use cases, running MinIO as a system service ensures it starts automatically and remains stable in production environments.
Here’s how to get MinIO up and running on a Linux server:
1/ Download MinIO:
cd /usr/share; wget https://dl.min.io/server/minio/release/linux-amd64/minio
chmod +x minio
sudo mv minio /usr/local/bin/2/ Create MinIO User and Directories:
sudo useradd -r minio-user -s /sbin/nologin
sudo mkdir /usr/local/share/minio
sudo mkdir /etc/minio
chown -R minio-user /usr/local/share/minio
chown -R minio-user /etc/minio3/ Set Environment Variables:
Create a file /etc/default/minio:
MINIO_VOLUMES="/usr/local/share/minio"
MINIO_ACCESS_KEY="myminioadmin"
MINIO_SECRET_KEY="S3cr3tP@ssword123456789"
MINIO_REGION="us-east-1"
MINIO_OPTS="--console-address :9001"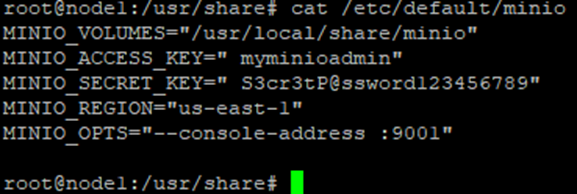
4/ Set Up MinIO Systemd Service:
Download the official service file:
wget https://raw.githubusercontent.com/minio/minio-service/master/linux-systemd/minio.service
sudo mv minio.service /etc/systemd/system/Reload systemd and start MinIO:
sudo systemctl daemon-reload
sudo systemctl start minio
sudo systemctl enable minioYour MinIO service should now be running, accessible at:
http://<your-server-ip>:9000
And the admin console at:
http://<your-server-ip>:9001
🌟 Create a Bucket for Elasticsearch Snapshots:
Now that MinIO is live, you’ll need a bucket — this is where your Elasticsearch snapshots will be stored.
+ Navigate to http://<your-server-ip>:9001.
+ Log in with your MINIO_ACCESS_KEY and MINIO_SECRET_KEY.
+ Click “Create Bucket” > Name it something like elasticsearch-backups.
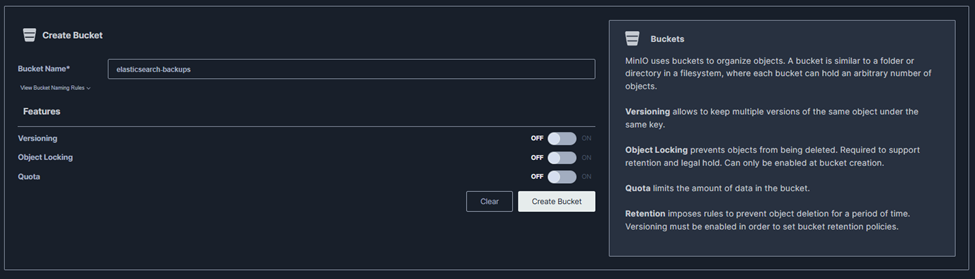
III/ Step 3: Securely Add MinIO Credentials to Elasticsearch Keystore and Automate S3 Repository Creation
Now that your MinIO server is up and running with a dedicated bucket for snapshots, it’s time to connect Elasticsearch to your S3-compatible storage — the secure way.
Hardcoding credentials in scripts or API calls might seem convenient, but it’s a dangerous habit, especially in production environments. That’s where the Elasticsearch keystore comes in.
Let’s walk through how to safely store your MinIO credentials and automate the process of creating your S3 snapshot repository.
🔒 What Is Elasticsearch Keystore?
The Elasticsearch keystore is a secure storage mechanism designed to hold sensitive settings, such as:
- Cloud storage credentials (like AWS S3 or MinIO keys).
- SSL certificate passwords.
- Token secrets.
Anything confidential that shouldn’t appear in plaintext configuration files or API payloads belongs in the keystore.
Once your MinIO credentials are stored here, Elasticsearch can access them internally — meaning your backup automation remains clean and secure.
🚀 Adding MinIO Credentials to Elasticsearch Keystore:
On each node in your Elasticsearch cluster, run the following commands:
sudo /usr/share/elasticsearch/bin/elasticsearch-keystore add s3.client.default.access_key
sudo /usr/share/elasticsearch/bin/elasticsearch-keystore add s3.client.default.secret_keyYou’ll be prompted to enter your MinIO Access Key and Secret Key.

Once done, restart Elasticsearch to apply the changes:
sudo systemctl restart elasticsearchNow Elasticsearch can authenticate with your MinIO S3 storage without exposing any credentials in configurations or API calls.
🤖 Automate Repository Creation with create_s3_repo.py:
Edit config.ini
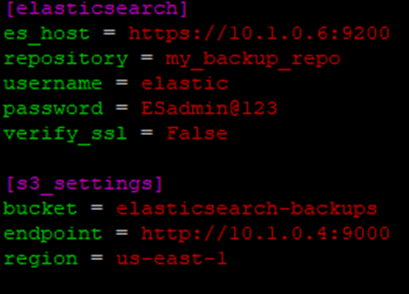
Navigate to the folder where your script is located and execute:
cd /path/to/your/scripts
python3 create_s3_repo.pyThe script will ask you to enter a name for your Elasticsearch snapshot repository:
Type a descriptive name, for example: minio_backup_repo

If everything is set up correctly, you’ll see a message like this:
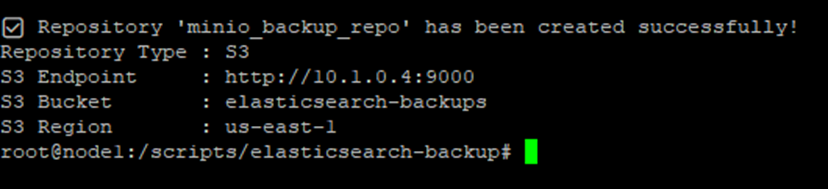
IV/ Step 4: Automate Elasticsearch Snapshots to MinIO S3 with a Simple Script
🚀 How Does Elasticsearch Snapshot Work?
Elasticsearch snapshots aren’t like traditional database backups. They’re designed to be:
- Incremental:
The first snapshot is a full backup, but every snapshot after that only saves the data that has changed since the last one. This makes backups fast and efficient. - Immutable:
Snapshots are read-only. Once created, they can’t be modified — ensuring backup integrity. - Stored Externally:
Snapshots are saved outside the cluster, in storage like S3 (or MinIO), so they remain safe even if your cluster goes down.
In short, after your first full backup, Elasticsearch quietly handles incremental updates in the background — you just need to tell it when to create a snapshot.
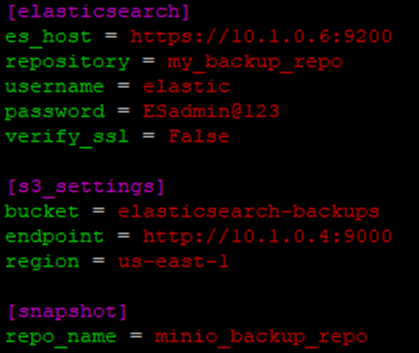
📂 Updated config.ini with Repository Name:
We’ll add a new section to store your snapshot repository name:
Navigate to your script directory > Run the script:
cd /path/to/your/scripts
python3 daily_snapshot.pyYou’ll see output like:


📄 List Snapshots in Elasticsearch (Name + Size) Using curl:
To view all snapshots in a specific repository along with their sizes, you can use the following curl command:
curl -u elastic:your_password -X GET "https://localhost:9200/_snapshot/minio_backup_repo/_all?pretty" --insecure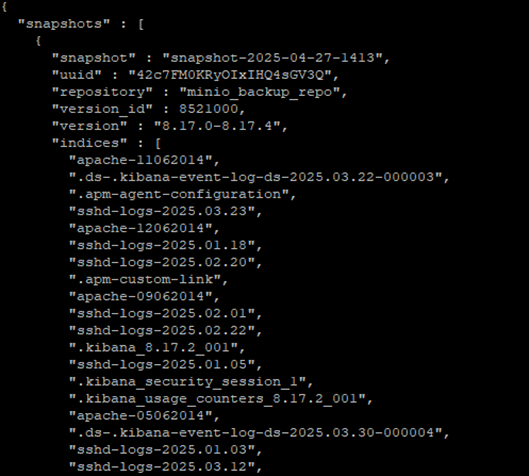
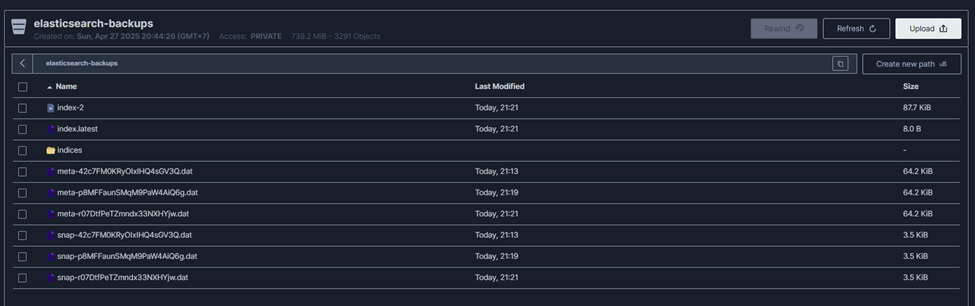
Once you’ve triggered your first snapshot, Elasticsearch has already stored a full backup of your indices in the MinIO bucket.
Now, let’s see how Elasticsearch’s incremental snapshot mechanism works in practice. Start by running your snapshot script again to create a second backup:

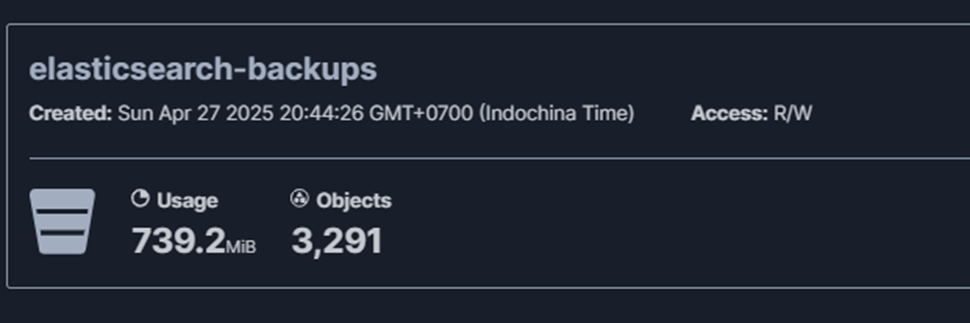
This will generate a new snapshot with a unique timestamp. Even though you’re backing up the same data, Elasticsearch is smart — it won’t duplicate unchanged data. Instead, it will only store the differences since the last snapshot.
To verify this, open your MinIO console > the number of objects and total storage used doesn’t double. That’s because Elasticsearch snapshots are incremental by design
V/ Conclusion: A Smarter Way to Backup Elasticsearch with MinIO S3:
In today’s world, where data is at the heart of every operation, having a reliable and efficient backup strategy for your Elasticsearch cluster isn’t just a best practice — it’s a necessity.
Through this guide, we’ve walked step-by-step from setting up your own S3-compatible storage with MinIO, to securely connecting Elasticsearch using the keystore, and finally automating your snapshot process with simple Python scripts.
Here’s what you’ve achieved:
- ✅ Deployed a lightweight, cost-effective storage solution without relying on external cloud providers.
- ✅ Secured your credentials properly, avoiding risky hardcoding practices.
- ✅ Automated both the creation of your snapshot repository and regular backups — ensuring your data is always protected.
- ✅ Leveraged Elasticsearch’s incremental snapshot mechanism to save storage space while maintaining frequent backups.
If you found this guide helpful, stay tuned for more practical DevOps solutions and automation tips here on TechNoStress.blog — where we make complex systems simple and stress-free.
Feel free to share your setup experience or ask questions in the comments below!
“Why worry about backups, when automation does the thinking for you? Work smart, not stressed.”
⚙️💡 — TechNoStress.blog
While setting up automated backups is essential for protecting your Elasticsearch data, it’s only part of what you can achieve with the ELK Stack. If you’re looking to put your Elasticsearch cluster to work in security operations, check out our guide on using ELK Stack to analyze SSH logs for SOC monitoring. It’s a practical walkthrough on turning raw log data into actionable security insights.
👉 How to Use ELK Stack to Monitor and Analyze SSH Logs for SOC


